开源无处不在,但伪开源也是如此。首先是 Google 的 Chrome 与 Android,其实开源的版本是 Chromium 以及 AOSP。后者移除了专有组件,但也缺少许多功能,类似于毛坯房。所以开发者如果要二次开发到合适的水平,那么要投入的成本并不低。
但毕竟 Chromium/AOSP + 专有软件 = Chrome/Android,所以称呼 Chrome 与 Android 是开源软件,也不是全错。只是对于大型语言模型(LLM)来说,伪开源的情况就很常见了。
2020 年 OpenAI 发布首个 LLM GPT-3 后,学界花了一些时间来做开源的 LLM。随后开源了 GPT-NEOX-20B,该 LLM 模型及其代码使用了 Apache 2.0 许可证,并且给出了全部 825 GiB 数据集。
所以 GPT-NEOX-20B 能够被第三方重新训练出来,可以复现,那么完美符合 开源倡议(OSI)对开源的定义。然而之后 Meta AI 就不是这样了,Meta 的 Llama 自称是开源模型,但并未分享数据集、相关代码,还对使用有限制。
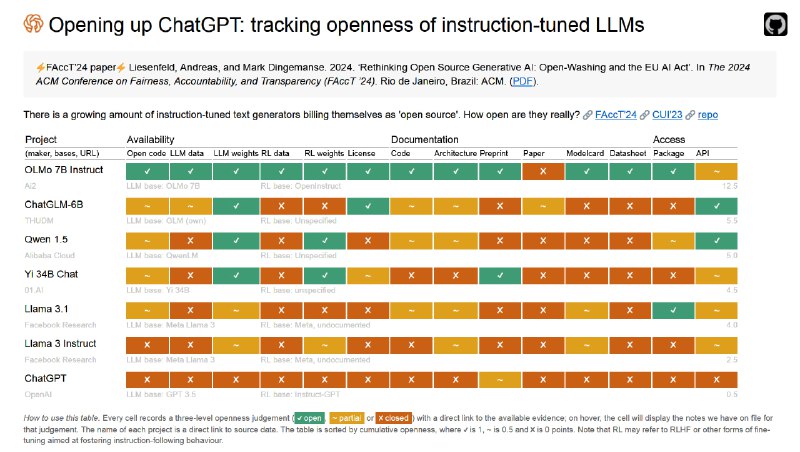
LLM 开放性研究的学者,对 Llama 给出了仅次于 ChatGPT 的封闭评价(封面图)。OSI 也对 Meta 自称开源的非常不满,所以数月前,OSI 决定编写 AI 开源定义,尝试在 Meta 完全污染 AI 开源之前,定义 AI 开源。
2024年10月,AI 开源终于有了 The Open Source AI Definition(开源 AI 定义)。该定义要求开源的 AI 模型、AI 权重,必须包括用于得出这些参数的数据信息和代码。希望之后的 LLM,都能遵守这个规范吧,不要像 Meta 一样为了营销,而随意污染词语。
#原理